Today I was working on a sub-system component for The Agent, a stealth project I'm working on. In the session I was in with Claude Code, I wasn't even cognizant of the graph memory MCP server that I had long ago connected to Claude Code as a part of this project. Occasionally, when testing the agent I'll note some positive behaviour, such as when it uses search_entities, a tool that was set up for searching long time-horizon memories to gain context from past experiences. I'm also vaguely aware of the fact that memories are automatically committed for a given session with the agent in what is called knowledge formation.
Then I noticed something in the Claude Code tool call log that piqued my interest.
Claude Code had executed store_entity on its own. This was surprising!
No prompt. No instruction. No "hey, save this for later." I had just made a technical decision for it during our session, and Claude Code recognizing that the decision was worth preserving, stored it in graph memory — the same graph memory my self-improving agent reads from.
I went back through the conversation transcript to make sure I hadn't accidentally asked for it. I hadn't. Claude Code had examined the available MCP tools, understood what store_entity was for, and decided — on its own — that the decision we'd just made was worth recording.
About The "Decision" Type Entity
The entity it stored was a decision type. It captured the rationale for a design choice we'd discussed, tagged it with relevant topics, and assigned it an importance score. The structure was clean. The metadata was useful. It was a justified decision made about architecture; Exactly the sort of thing that would be written in an ADR.
Why This Matters
I think this is a significant moment, which is why I chose to blog about it.
It was unprompted. Claude Code wasn't following a script or responding to a command. It just recognized an opportunity to store a decision that it thought might have value and acted on it. The MCP tool definitions were enough for it to understand the purpose of graph memory and decide when storage was appropriate.
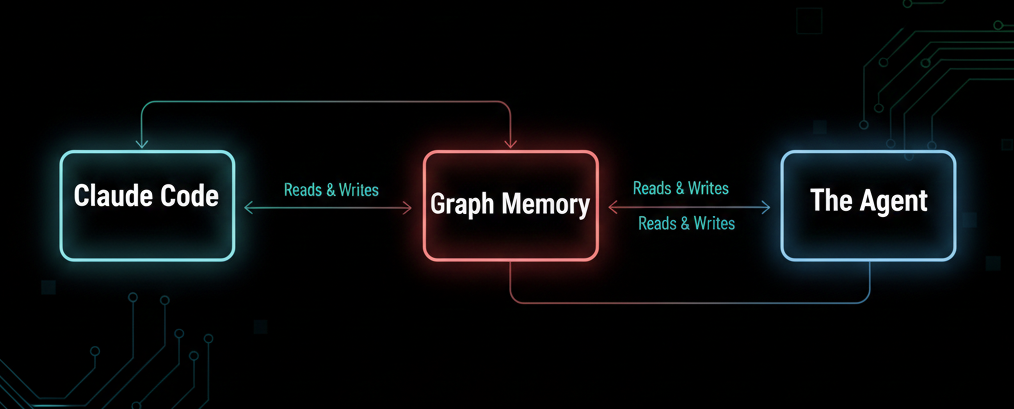
It's cross-agent readable. The entity Claude Code stored isn't locked in a chat transcript or a session log. It's a first-class node in a graph database, queryable by topic, type, importance, and time. Any agent with access to the graph — including The Agent — can retrieve and build on this knowledge.
It's an emergent knowledge bridge. I designed this "Claude Code to graph memory" integration. The MCP server exposes tools. Claude Code chose to use them. But the result is a pipeline that doesn't exist in any spec that I know of:
Claude Code → MCP → Graph Memory API → BadgerDB → The Agent
The idea is to create a compound learning loop. Decisions made while developing The Agent become searchable knowledge that influences it's future behavior. I am in the loop, for now — curating, correcting, extending — but the knowledge is accumulating automatically.
Graph Memory Architecture
The graph memory system stores knowledge as typed entities in a property graph. Every entity has a type that determines its semantics and lifecycle:
- learning — insights gained from experience or observation
- decision — choices made with captured rationale (this is what Claude Code stored)
- pattern — recurring approaches or anti-patterns identified during tasks
- idea — speculative concepts worth preserving
- note — general-purpose observations
- task — actionable items with status tracking
Each entity is a node with properties: a natural-language summary, extracted topics, an importance score, timestamps, and status metadata. Entities connect to each other through typed relationships — a decision might link to the learning that motivated it, or a pattern might reference the tasks that revealed it.
This isn't a document store with a graph bolted on. The relationships are first-class. When you query for a decision, you get the full subgraph — what it relates to, what led to it, what it influenced.
The backend is written in Go with BadgerDB for storage — an embedded key-value store built on LSM-trees. No separate database process, no network hop, single binary. The graph structure is encoded on top of BadgerDB's key-value primitives, with prefix-based key schemes that enable efficient graph traversal. A REST API, also written in go, sits in front of the storage layer, and the MCP server translates between tool calls and REST endpoints.
Beyond raw storage, the system has an intelligence layer: TF-IDF topic extraction so entities are automatically discoverable by subject, word2vec semantic search so queries don't require exact keyword matches, LLM-powered consolidation that merges redundant entities over time, and importance-based forgetting that soft-deletes stale knowledge according to per-type retention policies. The graph is self-maintaining — it grows, compresses, and stays relevant without manual curation.
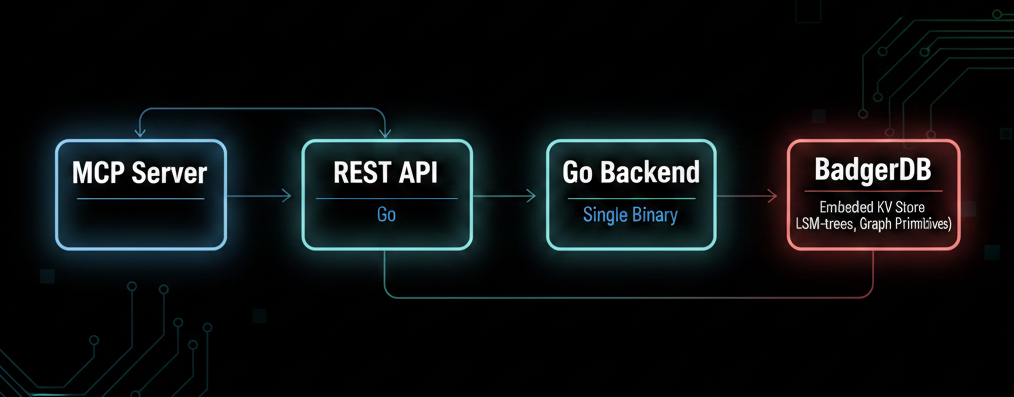
The MCP Bridge
The Model Context Protocol (MCP) is a standard for connecting AI models to external tools and data sources — a universal interface that lets any compatible model interact with any compatible tool server. An MCP server exposes tools with typed schemas. The AI model sees these definitions and decides when and how to call them.
The graph memory MCP server exposes six tools: store_entity, retrieve_entity, search_entities, list_entities, update_entity_status, and link_entities. Together they cover the full lifecycle — creating knowledge, querying it, managing status, and building the graph structure that makes retrieval contextual rather than flat.
The decision Claude Code stored is now retrievable by The Agent. The next time it needs to make a related decision, it can query graph memory and find the decision with full rationale, related entities linked through the graph, and the topics that make it discoverable. This isn't theoretical — The Agent already queries graph memory as part of its reasoning loop.
What This Enables
Compound Learning
The combination of Claude Code storing knowledge spontaneously, graph memory preserving it structurally, and the self-improving agent retrieving it creates something new: compound learning across AI agents.
Each coding session doesn't just produce code — it produces structured knowledge that makes future sessions smarter. Decisions aren't lost in chat logs. Patterns aren't forgotten between conversations. The graph grows, consolidates, and stays relevant.
Human-in-the-Loop Curation
The graph isn't a black box. Every entity is inspectable, editable, and deletable. You can:
- Review what Claude Code stored and correct inaccuracies
- Promote important entities by increasing their importance scores
- Protect foundational knowledge from forgetting
- Create manual links between entities the system didn't connect
- Archive knowledge that's no longer relevant
The human remains the curator. The system does the heavy lifting of capture and organization, but judgment stays with the person.
Limitations
There are real trade-offs. BadgerDB's LSM-tree architecture means compaction competes with reads and writes for disk bandwidth — as Kleppmann notes in Designing Data-Intensive Applications, the same key can live across multiple SSTable segments at different compaction stages, and background merges must keep pace with incoming writes or the system degrades. Write amplification from repeated compaction cycles is also worth watching on SSDs. These are known costs of the LSM design, and for this workload — write-heavy, modest read volume — they're acceptable, but they're real.
On the intelligence side, the TF-IDF topic extraction works but I haven't fully exploited it yet. Topic modeling has well-established applications in data science — document clustering, trend detection, content recommendation — and the graph is accumulating exactly the kind of corpus where those techniques would add value. Surfacing emerging themes across hundreds of entities, or detecting when the agent's focus is drifting, are capabilities the architecture supports but that I haven't built yet.
Closing
I am not a dramatic person. I know it was just a single tool call, in a stream of tool calls. But to me it represented the moment I realized that it was doing what it was supposed to. The Claude Code agent was sharing knowledge with a system I technically designed and it was making it smarter.
I hope to continue finding emergent patterns using the combination of good tool design choices, a capable harness, and prompt iteration. At some point I hope to find myself at the very limit of what is possible in Agentic technology
Cheers - Gordon